 c7娱乐
c7娱乐
(图片来源:Meta AI)
就在今天凌晨,Meta和OpenAI打响了硅谷 AI 大模型保卫战。
钛媒体App 7月24日报道,美国科技巨头Meta今晨推出迄今为止性能最强大的开源大模型——Llama 3.1 405B(4050亿参数),同时发布了全新升级的Llama 3.1 70B和8B模型版本。
Llama 3.1 405B支持上下文长度为128K Tokens,在基于15万亿个Tokens、超1.6万个H100 GPU上进行训练,这也是Meta有史以来第一个以这种规模进行训练的Llama模型。研究人员基于超150个基准测试集的评测结果显示,Llama 3.1 405B可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等业界头部模型相比较。
Meta创始人、首席执行官马克·扎克伯格 (Mark Zuckerberg) 称Llama 3.1为“最先进的”模型,他认为Meta正在建造的 Llama 模型是世界上最先进的,且表示Meta 已经在开发 Llama 4。甚至扎克伯格还亲自写了篇长文《Open Source AI Is the Path Forward》,发出了“开源引领 AI 行业、新时代”的声音。
但与此同时,OpenAI坐不住了。就在今晨,OpenAI宣布,今年9月23日之前,性能最强的小模型GPT-4o mini微调版全面免费,GPT-4o mini的输入Tokens费用比GPT-3.5 Turbo低90%,输出Tokens费用低80%。
一场在美国硅谷的 AI 大模型军备竞赛已经进入白热化。
全球性能最强4050亿开源大模型Llama 3.1来了,算力成本高达数亿美金
具体来说,Meta Llama 3.1 405B,是全球迄今为止性能最强大、参数规模最大的开源模型,在基于15万亿个Tokens、超1.6万个H100 GPU上进行训练。
Meta表示,为了能够以这种规模进行训练并在合理的时间内取得成果,团队显著优化了整个训练堆栈,并将模型训练推向超过 16,000 个 H100 GPU,使 405B 成为第一个以这种规模训练的 Llama 模型。
同时,与之前的 Llama 版本相比,Llama 3.1提高了用于训练前和训练后的数据的数量和质量。这些改进包括为训练前数据开发更仔细的预处理和管理流程、开发更严格的质量保证以及训练后数据的过滤方法。
另外,为了支持 405B 规模模型的大规模生产推理,团队还将模型从 16 位 (BF16) 量化为 8 位 (FP8) 数字,有效降低了所需的计算要求并允许模型在单个服务器节点内运行。
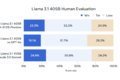
而且,Meta评估了超150个基准数据集的性能,Llama 3.1 405B在常识、可操作性、数学、工具使用和多语言翻译等一系列任务中,可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra相媲美。


在其他场景中,Llama 3.1 405B进行了与人工评估的比较,其总体表现优于GPT-4o和Claude 3.5 Sonnet。另外,升级后的Llama 3.1 8B和70B模型,相比于同样参数大小的模型性能表现也更好。
Meta透露,其更新了许可证,允许开发人员首次使用包括405B参数规模的Llama模型的输出来改进其他模型。截至目前,已经有超过25个企业推出了基于Llama 3.1开源版本的新模型。其中,亚马逊AWS、Databricks和英伟达正在推出全套服务,AI芯片创企Groq等为Meta此次发布的所有新模型构建了低延迟、低成本的推理服务,而Scale AI、戴尔等公司已准备好帮助企业采用Llama模型并使用自己的数据训练定制模型。
扎克伯格认为,Llama 会成为开源 AI 的行业标杆,就像当年的 Linux 一样。Llama 3.1 405B不仅是最强开源模型,还有望实现开源和闭源距离大大缩短的模型技术。

算力层面,Meta 在 AI 方面的投资一直很大。扎克伯格表示,Meta 的 Llama 3 模型的训练计算能力花费了“数亿美元”,但他预计未来的模型成本会更高。他说,“展望未来,计算能力将达到数十亿美元”。
2023 年,Meta 试图控制其在未来技术和管理层上的部分支出,在扎克伯格称之为“效率年”的一年中削减了数千个工作岗位。但扎克伯格仍然愿意在 AI 军备竞赛上花钱。
Meta 在 4 月份告诉投资者,今年计划花费比最初预期多数十亿美元的资金,其中一个核心原因是对 AI 的投资。据公司博客文章称,预计到今年年底,该公司将拥有约 350,000 个英伟达H100 GPU。而H100 芯片已成为用于训练 Llama、GPT-4等大模型的基础技术成本,每个芯片的成本可能高达数万美元。
值得一提的是,Meta还宣布使用其 Llama 模型作为Meta AI提供支持,该机器人将在其应用(包括 Instagram 和 WhatsApp)内也作为独立产品支持运行。
而且,Meta AI也适用于雷朋Meta智能眼镜,并将于下个月在美国和加拿大的Meta Quest上以实验模式推出。Meta AI将取代Quest上当前的语音命令,让用户可以免提控制耳机、获取问题的答案、随时了解实时信息、查看天气等。
用户还可以将Meta AI与在头显中看到的视图结合使用,比如询问其在物理环境中看到的事物相关情况。
扎克伯格表示,Meta AI拥有“数亿”用户,并预计到今年年底它将成为世界上使用最广泛的聊天机器人。另外,他认为,Meta 之外的其他人将使用 Llama 来训练他们自己的 AI 模型。
扎克伯格还公布公开信,直言开源对开发者、Meta、世界都更有利,使得与OpenAI之间的开源、闭源大模型之间的火药味更浓了。

扎克伯格提到,开源与闭源模型之间的差距正在逐渐缩小。他预计,从明年开始,Llama模型将成为业内最先进的模型。并且当下Llama系列模型已经在开放性、可修改性和成本效益方面处于领先地位。
在博客中,他还回答了为什么开源AI对开发者有利、为什么开源AI对Meta有利、为什么开源AI对世界有利这三大问题。
为什么开源AI对开发者有利?开发者需要训练、微调自己的模型,以满足各自的特定需求;开发者需要掌控自己的命运,而不是被一家封闭的供应商所束缚;开发者需要保护自己的数据;开发者需要高效且运行成本低廉的模型;开发者希望投资于将成为长期标准的生态系统。开源AI对Meta的好处在于,Meta的商业模式是为人们打造最佳体验和服务,要做到这一点,他认为必须确保其始终能够使用最佳技术,并且不会陷入竞争对手的封闭生态系统。另外,出售AI模型访问权限不是Meta的商业模式,这意味着开源不会削减其收入、可持续性发展或继续投资研究的能力。开源 AI 对世界有利。开源AI会促使Meta将Llama发展为一个完整的生态系统,并有成为行业标准的潜力。我认为,开源对于 AI 的美好未来必不可少。与任何其他现代技术相比,AI 更具有潜力提高人类的生产力、创造力和生活质量,并加速经济增长,同时推动医学和科学研究的进步。关于开源AI模型安全性的争论,我认为是开源AI将比其他选择更安全。开源将确保全世界更多的人能够享受 AI 带来的好处和机会,权力不会集中在少数公司手中,并且该技术可以更均匀、更安全地应用于整个社会。
然而,尽管承诺开放 Llama,但扎克伯格和其他公司高管仍对用于训练 Llama 3.1 的数据集保密。
“尽管它是开放的,但我们也是为自己设计的,”他解释道。扎克伯格表示,Meta 正在使用来自 Facebook 和 Instagram 的公开用户帖子,以及该公司从其他公司获得许可的其他“专有”数据集,但没有透露具体细节。
对于中国大模型与美国 AI 之间的竞争,扎克伯格强调,美国在 AI 发展方面永远领先中国数年是不现实的。但他也指出,即使是几个月的微小领先也会随着时间的推移而“积少成多”,从而使美国获得“明显优势”。
“美国的优势是去中心化和开放式创新。有些人认为,我们必须封闭我们的模式,以防止中国获得这些模式,但我认为这行不通,只会让美国及其盟友处于不利地位。一个只有封闭模式的世界,会导致少数大公司和我们的地缘政治对手能够获得领先的模式,而初创公司、大学和小企业则错失机会。此外,将美国创新限制在封闭开发中,增加了我们完全无法领先的可能性。相反,我认为我们最好的策略是建立一个强大的开放生态系统,让我们的领先公司与我们的政府和盟友密切合作,以确保他们能够最好地利用最新进展,并在长期内实现可持续的先发优势。”扎克伯格表示。
OpenAI抢断Meta,直言要把 AI 模型价格打到0
在Meta公布Llama 3.1两个多小时之后,OpenAI也释放了一则重要消息:刚刚发布的GPT-4o mini微调版免费了。
OpenAI表示,今天,公司推出了GPT-4o mini微调功能,让其新的小模型在特定用例中的表现更加出色。同时,从现在起直到9月23日,GPT-4o mini每天可以免费微调,最高可达200万训练Tokens。超过200万训练Tokens的部分将按每百万Tokens 3.00美元收费。而从9月24日开始,微调训练将按每百万Tokens 3.00美元收费。
OpenAI指出,如果你目前正在微调GPT-3.5 Turbo,GPT-4o mini则更加实惠,拥有更长的上下文,以及更强的技术能力。
更实惠:GPT-4o mini的输入Tokens费用比GPT-3.5 Turbo低90%,输出Tokens费用低80%。即使在免费期结束后,GPT-4o mini的训练成本也比GPT-3.5 Turbo低一半。更长的上下文:GPT-4o mini的训练上下文长度为65k Tokens,是GPT-3.5 Turbo的四倍,推理上下文长度为128k Tokens,是GPT-3.5 Turbo的八倍。更聪明且更有能力:GPT-4o mini比GPT-3.5 Turbo更聪明,并且支持视觉功能(尽管目前微调仅限于文本)。GPT-4o mini微调功能向企业客户和Tier 4及Tier 5使用等级的其他开发者开放。你可以访问微调仪表板,点击“创建”,并从基模型下拉菜单中选择“gpt-4o-mini-2024-07-18”来开始免费微调GPT-4o mini。
奥尔特曼发推文表示,GPT-4o mini 以 1/20 的价格在 lmsys 上实现了与 GPT-4o接近的性能表现。他还希望大家能够多多使用GPT-4o mini微调版本。
当前,一场关于开源和闭源大模型的硅谷 AI 价格战持续延烧。
从Meta Llama 3.1系列模型的发布,可以看出开、闭源大模型之间的差距正在缩小,而且,相比于此前的Llama模型,此次新模型还让尽可能多的开发人员和合作伙伴使用Llama系列,这意味着更多的问题将随着不断更新得到解决。但是,到场景和应用中,开源模型的具体能力、适用的商业化落地等还需要时间来证明。
不过,有分析认为,Llama 3.1 405B的价格远远低于GPT-4同一模型能力的版本。因此,OpenAI正在面临一系列的挑战。
Llama 3.1 405B 在不同平台的价格: Fireworks: $3 input / $3 output / 1M tokens Together: $5 in / $15 out Replicate: $9.5 in / $9.5 out Groq: 仅支持企业用户对比一下: GPT-4o: $5 in / $15 out Claude 3.5 sonnet: $3 in / $15 out
调研机构FutureSearch日前发布一份关于OpenAI收入的报告文件称,OpenAI现在的年度经常性收入(ARR)达到34亿美金,但其中,一半以上的收入来自ChatGPT会员付费,而偏向企业和开发者端的API收入仅为5.1亿美元,占比仅为15%左右。
对于GPT-5,奥尔特曼表示,开发“GPT-5”还需要一些时间,这个模型可能仍处于早期开发阶段。但相较于GPT-4 而言,GPT-5将是“巨大飞跃”。
“我们目前持乐观态度,但还有很多工作要做。”奥尔特曼进一步解释称,GPT-5有复杂的算法工作需要处理。“我希望它能取得重大飞跃。GPT-4经常犯很多错误,比如在推理方面表现不佳,有时还会完全跑偏,犯下低级错误,就像连一个六岁孩子都不会犯的一样。”
(本文首发于钛媒体App,作者|林志佳,编辑|胡润峰)
 c7娱乐
c7娱乐